What Is Agentic Analytics?

The term "agentic analytics" is everywhere right now. Every BI vendor and data platform is claiming it. But most of the conversation focuses on incremental improvements: a chatbot on your dashboard, AI-generated SQL, natural language queries on a single database. The full potential is much bigger.
What "agentic" actually means
"Agentic" has a specific technical meaning. An AI agent works in a loop: it reasons about a task, uses tools to take action, evaluates the results, and decides what to do next. Its tools can be APIs, databases, search indexes, or other agents. This isn't specific to analytics. It's the same pattern behind coding agents, research agents, and customer support agents.
What makes "agentic analytics" interesting isn't the loop itself. It's what the loop enables when your tools are an organization's data and knowledge. Revenue numbers in the data warehouse. Business rules in Slack messages. Product decisions in Google Docs. Customer context in the CRM. Bug reports in Linear. Most AI analytics today can only touch one of these at a time. An agent can reach all of them in a single investigation.
Think about the questions knowledge workers actually ask:
- "What's the status of customer X?" You need contract data, support tickets, product usage, Slack conversations, and scheduled calls.
- "Why did churn spike in Q4?" You need usage metrics, NPS survey responses, support ticket themes, and customer call transcripts.
- "Are we ready to launch in Germany?" You need revenue data, compliance docs, localization status, the latest state of development tasks, and marketing briefs.
None of these are purely "BI questions" or purely "search questions." BI and enterprise search, two categories that have existed separately for decades, are becoming the same thing.
Finding context nobody asked for
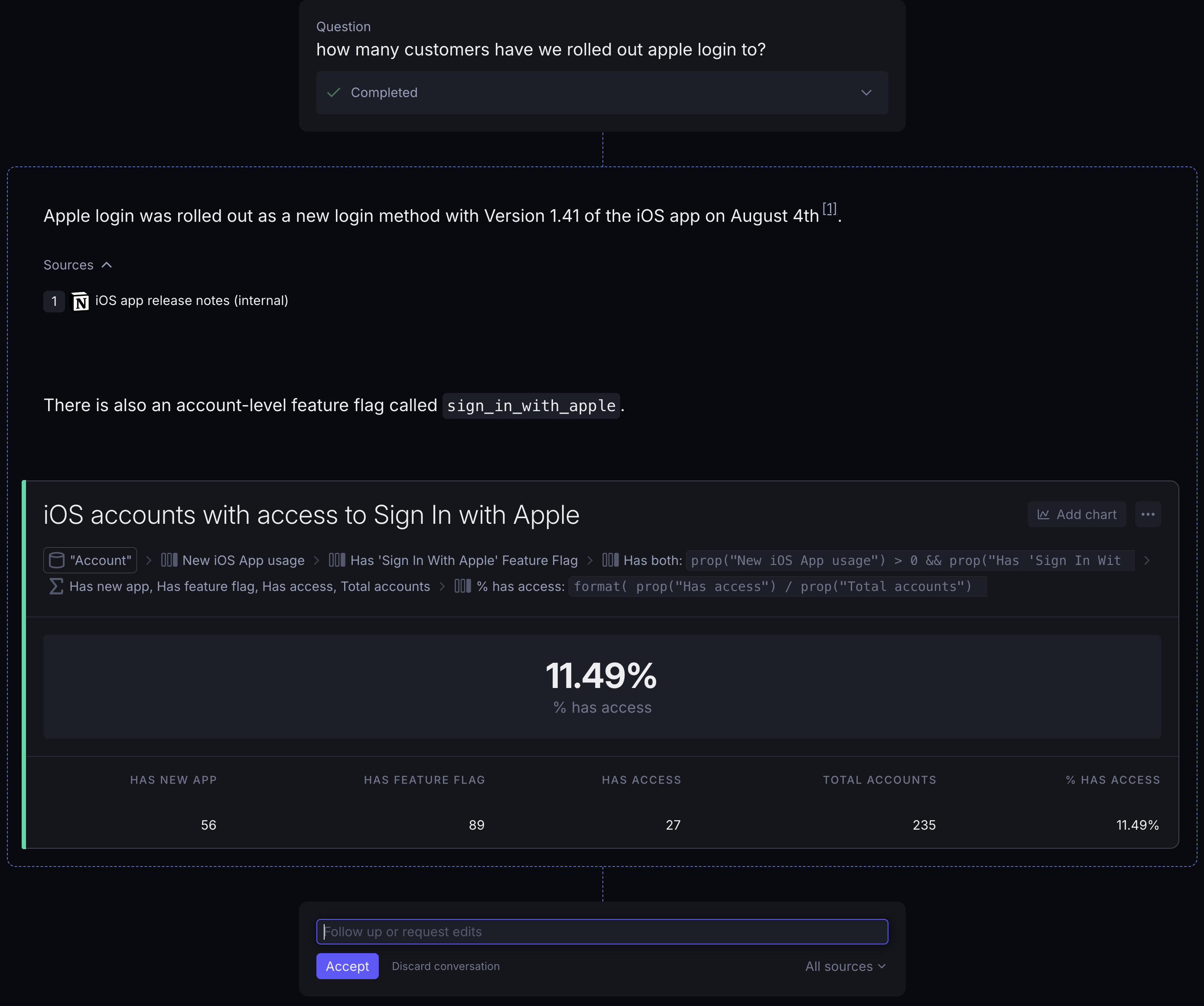
A user asks: "How many customers have we rolled out Apple login to?"
Seems like a simple question. But the real answer is surprisingly hard to get right. Apple login support was added in iOS app version 1.41, and it's gated behind an account-level feature flag. Customers on older app versions simply don't have the button. So a customer needs both: a new enough app version AND the feature flag enabled.
Point any "AI analytics" tool at your data warehouse, and it'll most likely find the feature flag. It'll count the accounts that have this, and give you an answer. It'll miss the business context of app releases entirely.
An analyst on your team would have this context. They might check the codebase or release notes for when this functionality came out.
And that's what an agent with your entire company's knowledge does. Nobody told it to check both conditions. It discovered both the feature flag and app version requirement on its own, combined both bits of data on each customer, and produced the real answer.
Tribal knowledge & data about data
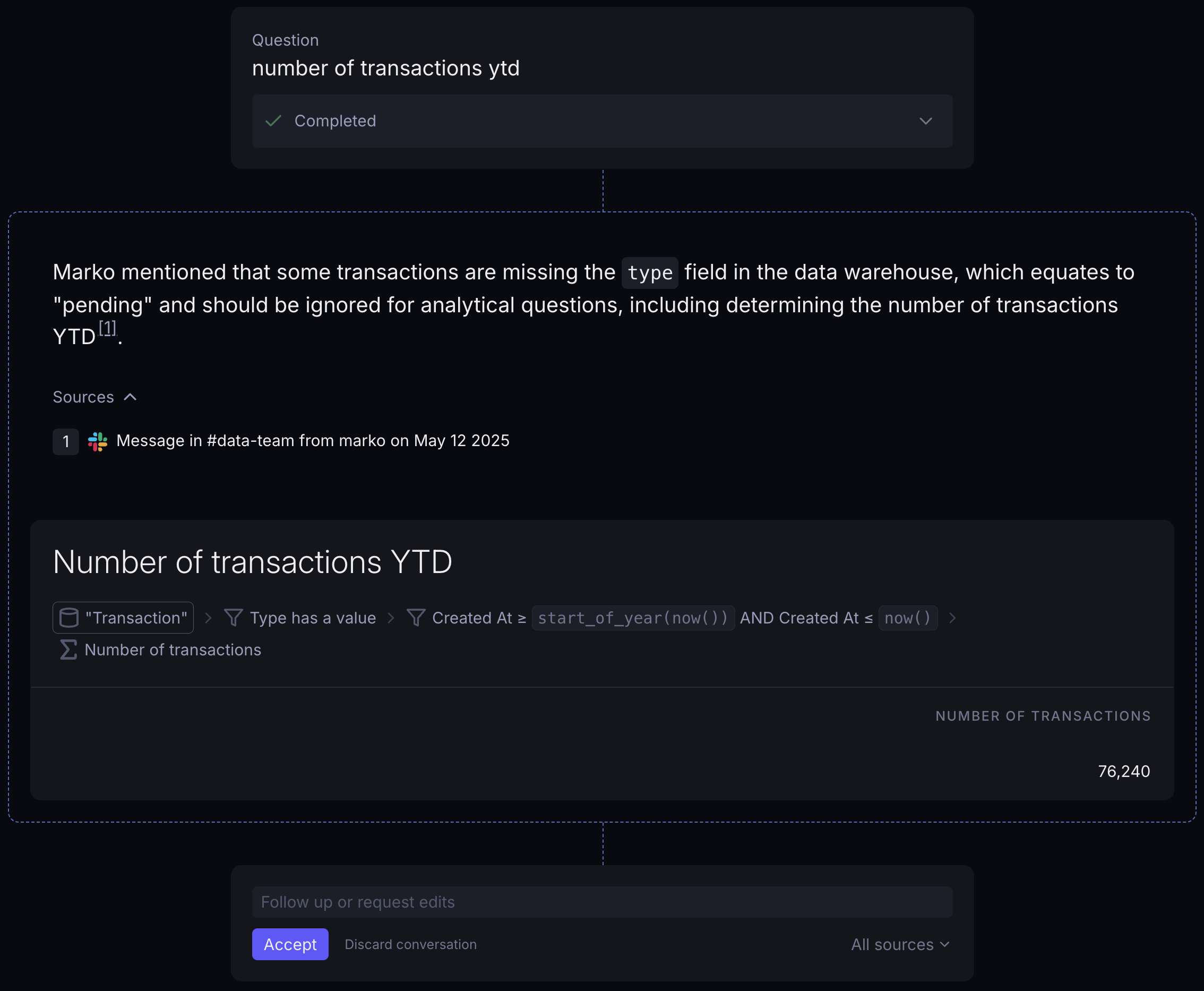
A user asks: "Number of transactions YTD." Sounds like an extremely simple question.
The agent returned 76,240. But here's what's interesting about how it got there.
While investigating the data, the agent found a message from a team member in the #data-team Slack channel from May 2025, noting that transactions missing the type field are actually pending transactions and should be excluded from most analytical queries.
In a perfect world, that business rule would be defined in your semantic layer. In the real world, half your business logic lives in someone's head or in a Slack message from six months ago.
Most AI analytics tools would have counted all transactions and confidently returned the wrong number.
Context engineering alone won't get you there
To solve for that "missing context", many teams have recently started to invest into "context engineering". Documenting everything in dbt models, curating semantic layers, annotating what's trusted, and building up knowledge bases.
This work is valuable, no doubt. But there's a limit to how far manual curation alone can take you.
Pre-defining metrics and dimensions for every question you anticipate is nearly equivalent to building dashboards for every question you anticipate. This, of course, is not feasible (or at least enough). You end up largely defeating the point of self-service: a curated set of answers to a curated set of questions, with everything else falling through the cracks.
Agentic analytics supplements this by pulling in additional context automatically. The agent found that Slack message not because someone had linked it to a certain metric, but because it was investigating the data and discovered relevant context along the way.
Manual curation and automatic context discovery work best together.
When agents get it wrong
More power means more ways to fail. An agent that can incorporate a Slack message into its analysis can also incorporate an outdated one.
Organizational knowledge changes constantly. Someone posts a rule in Slack, then six months later the business logic changes but nobody updates the original message. A good agentic system addresses this on two levels.
First, it can weigh source reliability. A central documentation page that's actively maintained is more trustworthy than a throwaway Slack message from a year ago. Second, it should surface all context it finds – including conflicting statements – along with exactly which sources it used.
At the end of the day, the AI's role is to give the user as much context as possible, for them to do their job.
Why explainability makes or breaks agentic analytics
No matter the data source, the biggest objection to AI analytics is trust. "How do I know the answer is right?"
Most tools solve this by showing you more AI output. Generated SQL. Reasoning traces. Step-by-step reasoning summaries.
In agentic systems, AI has already proofread its work a dozen times before handing it to the user. Yet, things still go wrong.
A sales leader isn't going to read the 70 lines of analytical SQL to detect the wrong definition of a region, or a missing event.
In a world where the AI's work isn't always perfect, the big unsolved problem is explainability for analytical work. When the agent queries your data warehouse, filters and transforms data, combines multiple sources, and produces a number or a chart – how do you verify that? Showing the generated SQL or Python is technically transparent, but practically useless for helping most people trust the answer.
The approach that we took at Supersimple is to make the work itself readable. Supersimple's agent works by using transparent, inspectable, no-code steps to analyze data. Each step shows exactly what data was pulled, how it was filtered, what formula was applied. Anyone can follow the logic.
It's almost always more reliable for a human to audit the actual actual work (and used sources) of an AI, instead of the AI's summary of why it was supposedly correct.
The more powerful your AI agent becomes, the more important it is that its output is auditable and explainable. You can't review everything the agent explored. But you need to be able to understand and verify the result it arrived at.
Evaluating agentic analytics tools
If you're evaluating tools that claim to be "agentic," here are the questions worth asking:
Can it reason across all of your relevant data sources? Not just databases. Documents, messages, codebases, tickets, CRM data. If it only works on structured data, it's BI with a chatbot, not the real promise of agentic analytics. And when the first result is incomplete, does it understand and investigate further, or does it stop?
Can you audit or follow its work? Ask something non-trivial and check: can a non-technical person understand how the agent arrived at it?
How does it handle outdated or conflicting information? If it pulls context from documents or messages, can it weigh source reliability? Does it surface conflicting statements, or does it silently pick one?
Does it learn and improve? When someone corrects an analysis, does that correction inform future work? An agent that makes the same mistake twice isn't learning.
Can your data team govern it? Look for semantic layers, permission models, and the ability to define which data sources and operations are available. The point of self-service BI was always to empower everyone while keeping the data team in control. Agentic analytics should do the same.
The questions behind the question
"How many customers have we rolled out Apple login to?" is rarely the real question. It's "Are we ready to make it the default?" or "Did this actually move users from desktop to mobile?" People discover their real question by iterating. Each answer reshapes what they ask next.
An agent with your full company context can follow that chain of thought with you; it understands the full picture.
It pulls the login data from your warehouse, rollout issues from support tickets, checks technical constraints in the codebase, and surfaces the launch plan from a Google Doc. Not answering isolated subqueries, but actually working the problem with you.
A thinking partner that has your entire company's context and knowledge. That's where agentic analytics is heading. Not "AI that writes SQL".