Intro to Semantic Layers
Ignoring AI, the engineering buzzword of the past few years has certainly been ‘the modern data stack’. We’ve had massive boatloads of cash invested into every aspect of the data life cycle, and the tooling we have access to now is better than ever.
Engineers enjoy engineering, and so a massive part of this investment – in terms of both time and money – has focused on the initial stages of handling data. This means going from a bunch of raw data scattered around, to clean-ish data in a high-performance cloud data warehouse.
As a result, companies have better data warehouses now than ever before! But does that mean the work is finished?
Well... data is meant to be a means to an end, not an end in itself. The second half of the story — actually utilizing all this incredible data to accomplish something — has arguably received less market excitement in recent years.

Semantic layers to the rescue?
There has been one notable exception to this lack of excitement, though – the magical promised land of a semantic layer. The semantic layer is meant to be the central definition layer for “what things mean”, and “how we calculate anything”.
While decentralizing everything and making systems modular is fun and makes engineers happy, the semantic layer is the one thing you want to have centralized. It’s meant to be the single, authoritative source of truth, after all!
A solid semantic layer gives us many benefits, including:
- Consistency: when your entire organization uses the same definitions, everyone stays on the same page. For every term your company uses, there are countless ways to interpret them when centralized definitions don't exist. How do we measure active users? What about the onboarding statuses, revenue churn or any other word we use?
- Avoiding duplicate work (DRY!): to avoid things getting out of sync and having engineers build the same things over and over again.
- Governance: having a centralized definition layer also gives you the potential to centralize access control and change procedures in an efficient way.
Moving beyond mere metrics
For most people, the most obvious starting point for a semantic layer is their metrics. Indeed, you should definitely know how many customers & how much revenue you have!
When most people talk about a semantic layer, they’re really talking about a metrics layer.
While metrics are useful, the harsh reality is that** most of your company’s data questions aren’t solely about metrics**.
Most of the value in data actually comes through deep data exploration – answering specific ad-hoc questions, not just slicing and dicing your KPIs.
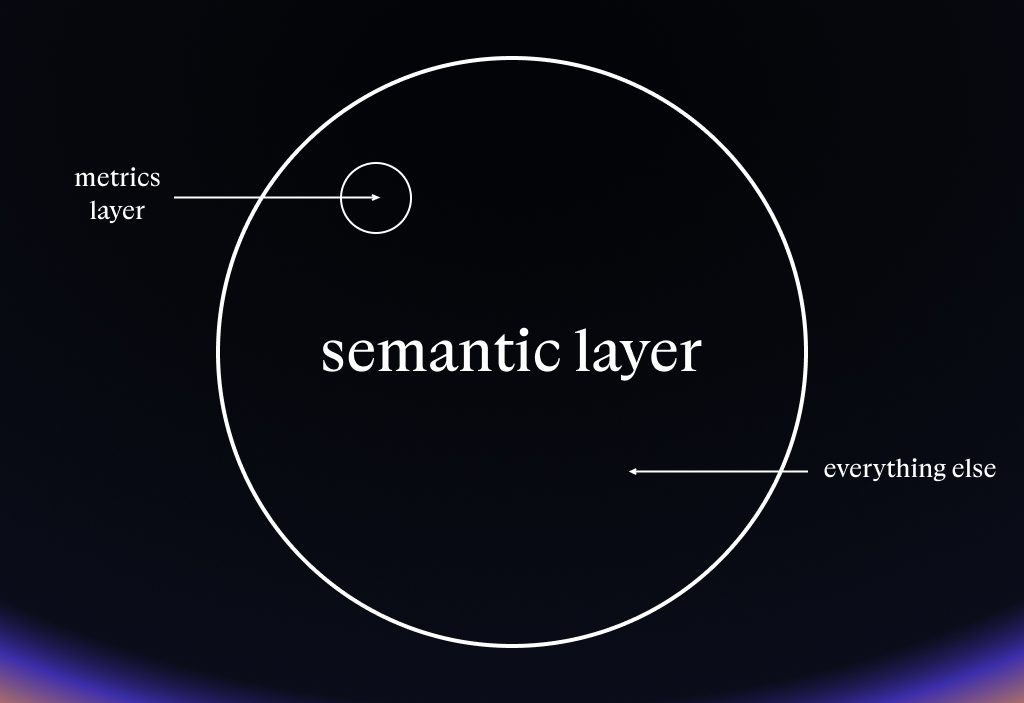
For this more impactful work, you most definitely need your core definitions and assumptions to be solid:
- How do we define user activation?
- How is churn and revival defined?
- Who even qualifies as a paying customer?
- How do we measure customer activity?
- What criteria do we use to filter out fraudulent transactions?
Whether you’re a data scientist working with code in a Jupyter notebook or someone like a PM or the Head of Growth answering complex questions through a data platform like Supersimple, you’ll want to make sure you’re holding your data right.
Data is more than numbers on a report
Your “monthly active users” metric is made up of real users with complex interactions with your system; it’s not just a single number that you can *maybe *break down by country. Those users themselves have relationships with other bits of your data: they invite teammates, order cabs, have tasks assigned to them, and eventually churn.
Just like you want all of your important metrics to be modeled out on the semantic layer, you need to do the same for the rest of your core business concepts.
If you’re on the data team at Uber, for example, you might want create entities for things like rides, drivers, ratings and scooters. Each of those things, then, are related to other entities! Scooters have a historic location trail, and a list of rides taken. There’s a price, possibly with subtotals, and a discount applied due to it being a Thursday.
Some semantic layers, such as Supersimple’s, let you build your metrics up from the core business concepts defined on your semantic layer. Having your definitions (such as metrics) built on top of other existing, trusted definitions can increase flexibility and reliability, reduce maintenance costs and provide more context for wherever you use them.
Starting small
For larger teams, creating an accurate & useful semantic layer can seem daunting. You can’t exactly sit down at your laptop and write all of it in one go!
This is where prioritizing efforts and getting to small, early wins can be helpful.
It’s often a good choice to start from the underlying definitions behind your core KPIs. For example, how do you even track revenue, or user/account activity metrics? Oftentimes, there are many hidden assumptions your team implicitly uses when it comes to these – assumptions that are all too easy to get misaligned on.
Formalize the way you filter out test accounts from your activity and revenue metrics, for example, and you’ll be well on your way to a robust, modern data stack.
Tools
High-level, you have two options for where to build and maintain your semantic layer logic: in separate tools or your overall data platform.
Dedicated semantic layer tools
dbt, originally a data transformation and database query materialization tool, has lately been trying to use its position as the market leader in data transformation to become a broader, metrics-focused semantic layer.
Cube.dev, originally an embedded analytics tool built to enable companies to quickly build complex reporting apps of their own, has also more recently repositioned itself as "The Universal Semantic Layer".
Defining the semantic layer inside your data platform
Some modern data platforms or business intelligence tools (including Supersimple) also have their own semantic layer. These can benefit from many of the same creature comforts as dedicated semantic layer tools, such as configuration as code.
The semantic layers built into or alongside modern self-service business intelligence tools or data platforms often feature tighter integration with the tools that teams use on a day-to-day basis to actually use data.
Speaking from our experience at Supersimple: if you're trying to go past the status quo and solve previously-unsolved customer problems with the product you're building, you'll need to have (some of) your own data modelling capabilities on the platform. For us, it's the only way we can offer a true self-service data analytics experience – because none of the other semantic layers come close in what they can do for these use cases.
For example, when you give a platform like Supersimple extra context on your data models, we're able to do things like dynamically use pre-aggregated data sources where available to improve performance, or enabling much more complex (custom) logic than generic data modeling tools ever could.
Choosing your approach
The case for using something like dbt as your tool-agnostic semantic layer is simple: avoiding vendor lock-in. While centralizing definitions for multiple tools is sometimes brought up as another argument, this one is less relevant, as tools (including Supersimple) generally let you use their semantic layers outside of the platform as well (e.g. via API or SDKs).
The case for defining your business semantics and metrics inside the platform(s) you'll be using them most in, is that this can enable a significantly better experience for your internal data consumers.
In reality, with the complex data stacks we see today, you are likely to mix the two approaches. Some of the work will be done in a more generic data modeling tool like dbt, and some of it will be done closer to your internal end users, e.g. in the data science team's own tooling, or inside the company-wide business intelligence tool.
Leveraging existing tooling instead of building in-house
Because making a semantic layer useful requires quite a bit more than just materializing some tables, it generally makes sense to use some existing tooling rather than re-building a whole data platform in-house.
Some of the most powerful modern data analytics platforms like Supersimple offer a tight integration with a semantic layer, meaning all of your metrics, ad-hoc explorations and alerts rely on the same gold-standard definitions.
To hop on a free consultation call with one of Supersimple's engineers to talk through how you could set up a semantic layer, you can book a technical consultation here. Or read more about Supersimple's semantic data modelling layer from our docs.